Implementing a simple pipeline with Typescript
Hi, this is Sushant from the Minma, Inc. tech-team and today I would like to demonstrate to you the power of Typescript.
In my last post, I introduced you to Apache Airflow and demonstrated the implementation of a pipeline to create a pizza using Airflow. Today, we will do the same, but with Typescript. The goal is to build a strongly typed pipeline utilizing Typescript's type system and create a variety of pizzas with it.
As you can probably tell, I am somewhat obsessed to pipelines. To me, pipelines are a great way to write code for some business process. Add static typing to pipelines and you get a pipeline that is robust, modular and flexible and readable. Let's say I work for an e-commerce site (which I actually do ;)) and we just got reports that our users never get any welcome email upon registration. Not knowing if it's a bug in the system or if we ever send emails in the first place, my product manager asks me if we are sending welcome emails when user registration is complete. Being a relatively new programmer in the company, I have no other way to answer that than go through the source code for and find out what happens during user registration. A lot of time this would involve going through a lot of code, jumping around from function to function trying to get to code that relates to the end of the registration process. If the same user registration process were implemented as a pipeline, I would be able to get a top level view of what goes on when a user registers at our site just by looking at the pipeline's steps. Chances are, there could actually be a step in the pipeline that reads "sendWelcomeEmail"! Even if that's not the case, I could just look at the pipeline and choose a step in the pipeline that I think could have a connection to emails and see what's going on.
Enough talk! Let's write ourselves a pipeline with Typescript.
Here's what we are gonna do:
- a. Implement a function that lets us create pipeline for any workflow.
- b. Use the function to create a pipeline for creating pizzas based on a user's order.
- c. Use the pipeline created in step b. to create various kinds of pizzas.
The source code for the pipeline is available in github
a. Implement a function that lets us create pipeline for any workflow.
We want our module to take in functions that represent each step in our pipeline and return a single composed function that performs those steps in order.
If f(x), g(x), h(x) and i(x) represent each step in our pipeline, the definition of our workflow would be
j(x) = i ( h ( g ( f ( x ) ) ) )
So, whenever we want to run our workflow, we don't directly call f(x), g(x), h(x), and i(x) in order every single time. All we need to do is call j(x) and the pipeline runs as expected.
Here is the definition in typescript:
export type Pipeable<Args, ReturnType> = (args: Args) => ReturnType;
export function createPipeline<X, A>(f: Pipeable<X, A>): Pipeable<X, A>;
export function createPipeline<X, A, B>(f: Pipeable<X, A>, g: Pipeable<A, B>): Pipeable<X, B>;
export function createPipeline<X, A, B, C>(f: Pipeable<X, A>, g: Pipeable<A, B>, h: Pipeable<B, C>): Pipeable<X, C>;
export function createPipeline<X, A, B, C, D>(f: Pipeable<X, A>, g: Pipeable<A, B>, h: Pipeable<B, C>, i: Pipeable<C, D>): Pipeable<X, D>;
export function createPipeline<X, A, B, C, D, E>(f: Pipeable<X, A>, g: Pipeable<A, B>, h: Pipeable<B, C>, i: Pipeable<C, D>, j: Pipeable<D, E>): Pipeable<X, E>;
export function createPipeline<X, A, B, C, D, E, F>(f: Pipeable<X, A>, g: Pipeable<A, B>, h: Pipeable<B, C>, i: Pipeable<C, D>, j: Pipeable<D, E>, k: Pipeable<E, F>): Pipeable<X, F>;
export function createPipeline<X, A, B, C, D, E, F>(
f: Pipeable<X, A>,
g?: Pipeable<A, B>,
h?: Pipeable<B, C>,
i?: Pipeable<C, D>,
j?: Pipeable<D, E>,
k?: Pipeable<E, F>):
Pipeable<X, A> |
Pipeable<X, B> |
Pipeable<X, C> |
Pipeable<X, D> |
Pipeable<X, E> |
Pipeable<X, F> {
if (!!k) {
return (args) => k(j!(i!(h!(g!(f(args))))));
} else if (!!j) {
return (args) => j(i!(h!(g!(f(args)))));
} else if (!!i) {
return (args) => i(h!(g!(f(args))));
} else if (!!h) {
return (args) => h(g!(f(args)));
} else if (!!g) {
return (args) => g(f(args));
} else {
return (args) => f(args);
}
}
Let's break this down one by one.
export type Pipeable<Args, ReturnType> = (args: Args) => ReturnType;
Pipable<Args, ReturnType> is a generic type for any function that takes in arguments of type Args and returns something of type ReturnType. We will be using this to generate your compose function.
Our main function createPipeline() has six overloads, one for each number of arguments passed to it. This implies that our create pipeline function can handle workflows having no more than 6 steps.
Let's look at one of these overloads:
export function createPipeline<X, A, B, C>(f: Pipeable<X, A>, g: Pipeable<A, B>, h: Pipeable<B, C>): Pipeable<X, C>;
If we were to visualize what createPipeline does, it would look something like this:
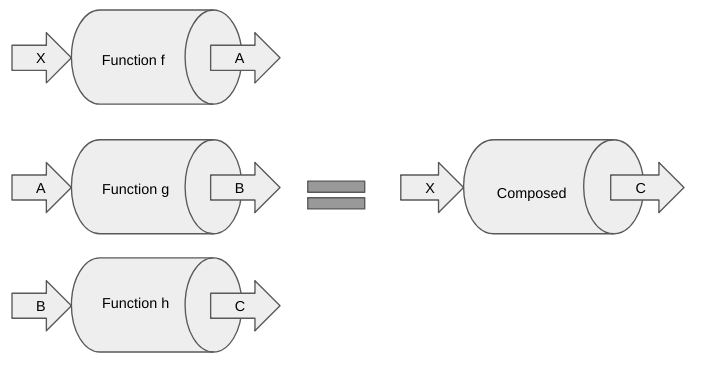
It takes in 3 functions f, g, and h and returns a new composed function that does the same thing as the three functions combined. Notice that the input of the composed function is the same as the input of the first step of the pipeline and the output is the same as the output of the last step of the pipeline. What this means is, instead of running f, g, and h in order everytime, we can just run this composed function every time we want to execute our pipeline and be assured that the result will be the same as running f, g and h combined.
if (!!k) {
return (args) => k(j!(i!(h!(g!(f(args))))));
} else if (!!j) {
return (args) => j(i!(h!(g!(f(args)))));
} else if (!!i) {
return (args) => i(h!(g!(f(args))));
} else if (!!h) {
return (args) => h(g!(f(args)));
} else if (!!g) {
return (args) => g(f(args));
} else {
return (args) => f(args);
}
↑This is not code that I am proud of, but in order to ensure that the types are inferred correctly, I had to write it this way.
What I really wanted to do was to implement a reducer like so
const reducer: <M, N, O>(f: Pipeable<M, N>, g: Pipeable<N, O>) => Pipeable<M, O> = (f, g) => (x) => g(f(x));
and use the reducer function to reduce an array of functions like
[f, g, h, i, j, k].reduce(reducer)
, but sadly Typescript wasn't so forigiving. If anybody has a more elegant solution, please enlighten me!
b. Use the function to create a pipeline for creating pizzas based on a user's order.
This is where we build the building blocks of our pipeline.
Let's first define what an order looks like:
export namespace OrderOptions {
export enum Crust {
HandTossed = "HandTossed",
Pan = "Pan",
ThinCrust = "ThinCrust"
}
export enum Sauce {
Tomato = "Tomato"
}
export enum Topping {
Ham = "Ham",
Cheese = "Cheese",
Pineapple = "Pineapple",
Mushroom = "Mushroom",
Pepperoni = "Pepperoni",
ItalianSausage = "Italian Sausage",
Olives = "Olives",
Jalapeno = "Jalapeno",
GreenPepper = "Green Pepper",
Anchovies = "Anchovies",
Onion = "Onion"
}
}
export interface Order {
crust: OrderOptions.Crust;
sauce: OrderOptions.Sauce;
toppings: OrderOptions.Topping[];
}
Customers can select from 3 types of crusts, sadly just one type of sauce and many different kinds of toppings. Our order object, as is obvious from the model, will have a value for crust, sauce and an array of toppings;
Our pipeline for creating a pizza will have the following 4 steps:
- Prepare crust.
- Apply sauce.
- Add toppings.
- Bake in oven.
Note that each step is dependent on the previous step. i.e. We cannot apply sauce if you have no crust. We don't add toppings if the sauce hasn't been applied yet, and so on.
Therefore, we define state for our pizza as follows:
type CrustPrepared = { crust: OrderOptions.Crust };
type SauceApplied = CrustPrepared & { sauce: OrderOptions.Sauce };
type ToppingsAdded = SauceApplied & { toppings: OrderOptions.Topping[] }
type FreshlyBakedPizza = ToppingsAdded & { baked: true };
type PizzaState = CrustPrepared | SauceApplied | ToppingsAdded | FreshlyBakedPizza;
As we can see, if our pizza is in the SauceAppliedstate, it will have properties from the CrustPrepared state and have one more property for the type of sauce applied. Note that if our pizza is in the ToppingsAddedstate, it will have properties from both the CrustPrepared state the SauceAdded state in addition to the property for the types of toppings used.
To make life easier, we define following type to represent the output at every step in the pipeline:
interface Output<CurrentState extends PizzaState> {
readonly order: Order,
pizzaState: CurrentState,
events: string[];
}
The order property represents the order made by the customer. We don't want the order to suddenly change when the pizza is half done, so we set it as readonly. The pizzaState property represents the current state in the pipeline. We also have an events property for logging purposes so that we can see that all the steps in the pipeline were properly executed and in order.
OK, let's start writing code for each step of the pipeline:
1. Prepare crust.
Our prepareCrust step looks like this:
const prepareCrust: Pipeable<Order, Output<CrustPrepared>> = (order) => {
return {
order: order,
pizzaState: { crust: order.crust },
events: [`Preparing ${order.crust} pizza crust......DONE`]
}
}
Remember that each function passed to our createPipeline function has type Pipeable. Thus, we define our prepareCrust function as Pipeable. We are not doing anything crazy. All we are doing is take the order, and set the pizzaState with crust set to the crust ordered by the user. We also add a message to log that this step completed successfully.
2. Apply sauce.
Similarly, our applySauce step looks like this:
const applySauce: Pipeable<Output<CrustPrepared>, Output<SauceApplied>> = (state) => {
return {
...state,
pizzaState: { ...state.pizzaState, sauce: state.order.sauce },
events: [...state.events, `Applying ${state.order.sauce} sauce......DONE`]
}
}
Things to note:
- This function takes the output of the
prepareCrust step as an argument.
- We are using the spread operator
...state to first create a copy of the current state, and then update the state in the copy with the new state.
3. Add toppings.
Our addToppings step looks like this:
const applyToppings: Pipeable<Output<SauceApplied>, Output<ToppingsAdded>> = (state) => {
return {
...state,
pizzaState: { ...state.pizzaState, toppings: state.order.toppings },
events: [...state.events, `Adding ${state.order.toppings.join(", ")} toppings......DONE`]
}
}
Nothing special here, similar to the applySauce.
4. Bake in oven.
Finally, our bakeInOven step looks something like this:
const bakeInOven: Pipeable<Output<ToppingsAdded>, Output<FreshlyBakedPizza>> = (state) => {
return {
...state,
pizzaState: { ...state.pizzaState, baked: true },
events: [...state.events, "Baking in oven......DONE", "Freshly baked pizza ready!!!!"]
}
}
Now that we have functions for each of our steps, let's create our pipeline:
export const createPizza = createPipeline(
prepareCrust,
applySauce,
applyToppings,
bakeInOven
);
We finally get to use our createPipeline function to create our pizza pipeline. Note that if we tried to change the order of the steps here, Typescript would not let us! This is where all the hard work of writing the overloads for createPipeline pays off.
This is the part that also shows the readability of pipelines. I could just look at this piece of code and have an idea about what steps are involved in creating a pizza. Of course, good naming goes hand in hand for that to work.
Notice that we are not exporting the individual steps. We are just exporting the composed createPizza function. So, if somebody wants to create a pizza, they have no choice but to adhere to our createPizza pipeline.
We can extend this concept and do things differently. Instead of having a generic createPizza for all types of pizzas, we could have a pipeline for each type of pizza we offer such as createHawaiianPizza or createMeatLoversPizza and so on. The possibilities are endless!
Now that we have our pipeline ready, let's order some pizzas:
const handTossedHawaiianPizza = createPizza({
crust: OrderOptions.Crust.HandTossed,
sauce: OrderOptions.Sauce.Tomato,
toppings: [OrderOptions.Topping.Ham, OrderOptions.Topping.Pineapple, OrderOptions.Topping.Cheese]
})
const thinCrustHawaiianPizza = createPizza({
crust: OrderOptions.Crust.ThinCrust,
sauce: OrderOptions.Sauce.Tomato,
toppings: [OrderOptions.Topping.Ham, OrderOptions.Topping.Pineapple, OrderOptions.Topping.Cheese]
})
const meatLoversPizza = createPizza({
crust: OrderOptions.Crust.Pan,
sauce: OrderOptions.Sauce.Tomato,
toppings: [OrderOptions.Topping.ItalianSausage, OrderOptions.Topping.Ham, OrderOptions.Topping.Pepperoni ,OrderOptions.Topping.Cheese ]
})
console.log("######### Hand Tossed Hawaiian pizza ##########")
console.log(handTossedHawaiianPizza)
console.log("###############################################\n")
console.log("######### Thin CrustHawaiian pizza ############")
console.log(thinCrustHawaiianPizza)
console.log("###############################################\n")
console.log("############# Meat Lovers pizza ###########")
console.log(meatLoversPizza)
console.log("###############################################\n")
All we are doing is passing an Order object to our createPizza pipeline and logging the results to the console.
To see if it works, compile with tsc and run.
If using the source code from github (assuming that Typescript is installed), you can test it like so:
# Inside the src directory
$ tsc && node bin/orderPizza.js
Output:
######### Hand Tossed Hawaiian pizza ##########
{ order:
{ crust: 'HandTossed',
sauce: 'Tomato',
toppings: [ 'Ham', 'Pineapple', 'Cheese' ] },
pizzaState:
{ crust: 'HandTossed',
sauce: 'Tomato',
toppings: [ 'Ham', 'Pineapple', 'Cheese' ],
baked: true },
events:
[ 'Preparing HandTossed pizza crust......DONE',
'Applying Tomato sauce......DONE',
'Adding Ham, Pineapple, Cheese toppings......DONE',
'Baking in oven......DONE',
'Freshly baked pizza ready!!!!' ] }
###############################################
######### Thin CrustHawaiian pizza ############
{ order:
{ crust: 'ThinCrust',
sauce: 'Tomato',
toppings: [ 'Ham', 'Pineapple', 'Cheese' ] },
pizzaState:
{ crust: 'ThinCrust',
sauce: 'Tomato',
toppings: [ 'Ham', 'Pineapple', 'Cheese' ],
baked: true },
events:
[ 'Preparing ThinCrust pizza crust......DONE',
'Applying Tomato sauce......DONE',
'Adding Ham, Pineapple, Cheese toppings......DONE',
'Baking in oven......DONE',
'Freshly baked pizza ready!!!!' ] }
###############################################
############# Meat Lovers pizza ###########
{ order:
{ crust: 'Pan',
sauce: 'Tomato',
toppings: [ 'Italian Sausage', 'Ham', 'Pepperoni', 'Cheese' ] },
pizzaState:
{ crust: 'Pan',
sauce: 'Tomato',
toppings: [ 'Italian Sausage', 'Ham', 'Pepperoni', 'Cheese' ],
baked: true },
events:
[ 'Preparing Pan pizza crust......DONE',
'Applying Tomato sauce......DONE',
'Adding Italian Sausage, Ham, Pepperoni, Cheese toppings......DONE',
'Baking in oven......DONE',
'Freshly baked pizza ready!!!!' ] }
###############################################
And that's it for this post! I hope I could demonstrate the usefulness of pipelines, especially with Typescript. I'm sure there are better ways to implement the same (and I would be all ears for better ways). Hopefully in a future post, I will be able to demonstrate a better way to implement the same pipeline, perhaps with some error handling and much cleaner code!
PS: We are hiring! For those interested, feel free to apply here . At least conversational Japanese proficiency is required.











