minmaの開発組織の話

突然ですが、
みなさんはサッカーは好きですか?
私は好きです。
観るのも、
やるのも、
どちらも好きです。
週末はつい試合を観てしまいますし、
ワールドカップの年になると、寝不足になります。
そして2026年。 またワールドカップがやってきます。
そんなタイミングもあって、
今回は少し変わった形で、
私たちの話を書いてみようと思いました。
こんにちは。
エンジニアリングマネージャーのユジンです。
技術の話をそのまま説明するのではなく、
サッカーに例えて、
開発組織の話をしてみようと思います。
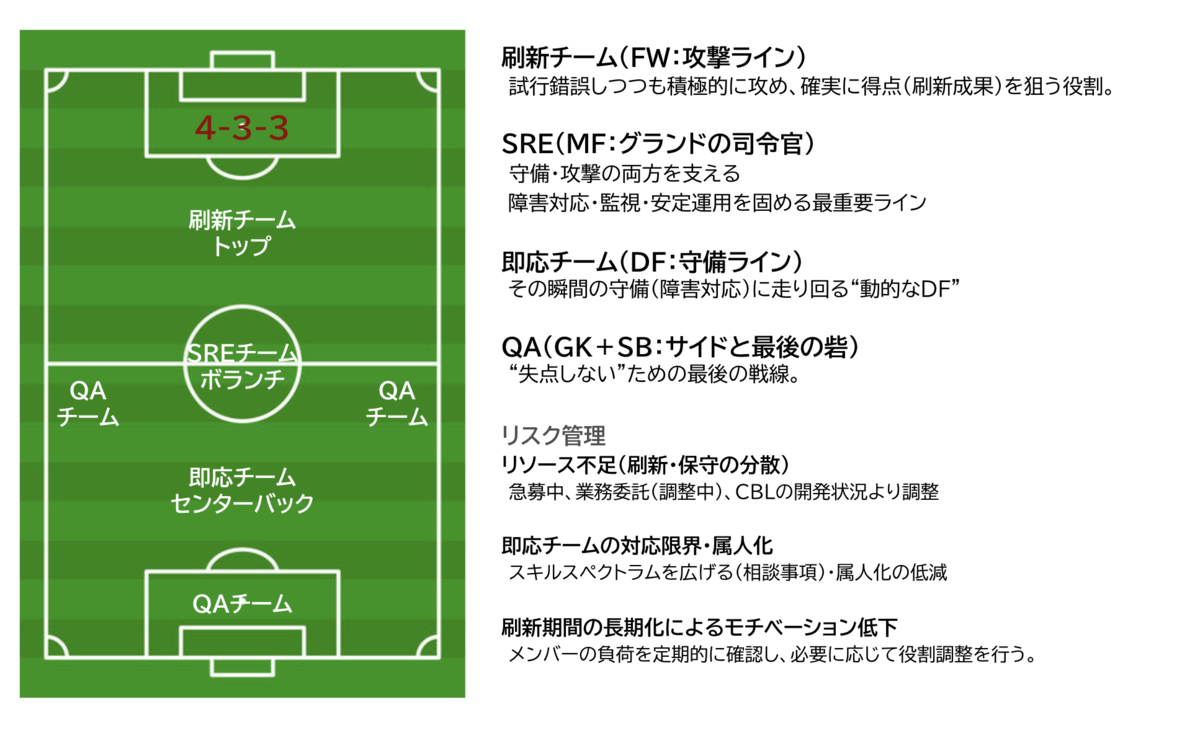
まず、この図を見てください。
一見するとフォーメーション図ですが、
実はこれは組織図です。
実際に、2026年の組織変更を検討した際に
私が社内共有で使っていた資料そのものです。
今日はその
「ある一試合」の話から始めたいと思います。
実はその試合、
今の開発組織の状況と、驚くほどよく似ていたんです。
第1部
1.キックオフ前
キックオフ10分前。
ナイトゲームのスタジアムは、まだ少しひんやりしていた。
ライトに照らされた芝は薄く湿っていて、踏むたびに小さな音がする。
観客席はゆっくりと埋まり始め、
ざわざわとした声が、波のように広がっていく。

オレンジ色のユニフォームを着た選手たちが、
ピッチの中央に集まった。
今日も、いつも通り。
誰かがストレッチをしている。
誰かがスパイクの紐を結び直している。
誰かは無言で空を見上げている。
やがて全員が肩を組み、スクラムを組む。
今日も、いつも通り。
同じフォーメーション。
同じメンバー。
同じ戦術。
最近の成績は2勝2敗。
悪くはない。
でも、突き抜けてもいない。
"いこう"
短い一言。
それだけで十分だった。
2.前半
ホイッスル。
試合開始。

立ち上がりは悪くなかった。
パスもつながる。
足も軽い。
"今日はいけるかもしれない"
そんな空気が、確かにあった。
でも、10分を過ぎたあたりから、
少しずつ違和感が出てくる。
相手のプレスが速い。
ボールを受けた瞬間、もう寄せられている。
奪われる。
追いかける。
また守る。
気づけば、自陣に押し込まれていた。
攻撃の時間がほとんどない。
ずっと走っているのに、なぜか前に進めない。
前半18分。最初の失点。
ゴールネットが揺れる。
その音だけが、
やけに大きく聞こえた。
一瞬、誰も声を出さない。
"まだ1点だ。"
誰かが手を叩く。
無理やり前を向く。
再開。
でも流れは変わらない。
前半30分、
2失点目!
足が重くなってきた。
呼吸が荒い。
それでも、まだ心は折れていなかった。
前半終了間際。
やっと訪れたチャンス。
左サイドを抜け出し、クロス。
ダイレクトシュート。
ゴールキーパーの指先に触れ、ポストをかすめて外れる。
"うわっ…!"
スタジアム全体が息を飲む。
入っていれば、流れは変わったかもしれない。
でも、入らなかった。
それでも、そのワンプレーが妙に希望に見えた。
"いけるかもしれない"

根拠はない。
でも、そう思いたかった。
そして
追加点。
0 : 3
スコアボードの数字が、
冷たく光る。
3点差。
苦しい。
でも、まだ終わった気はしなかった。
"1点返せば、流れは変わる"
誰もが、
そう信じてロッカールームへ向かった。
3.ハーフタイム
汗が引いて、急に寒くなる。
床に座り込み、うつむく選手。
無言で水を飲み続ける選手。

監督がホワイトボードを出す。
"攻撃の枚数、増やす。"
"全員、前に出る。"
"ゴールを取りにいくしかない。"
冷静な分析というより、決断だった。
3点差。
その現実が、判断を急がせた。
リスクがあることは、みんな分かっていた。
でも、他に手が思いつかなかった。
後半
ラインが一気に上がる。
守備のはずの選手も前へ。
ボールを奪ったら、とにかくロングボール。
つなぐ余裕はない。
ただ前へ。
ただ遠くへ。
祈るようなパス。
でも、そのほとんどは相手に跳ね返される。
その瞬間、後ろはがら空き。
サイドバックが全力で戻る。
また戻る。
何度もスプリント。
肺が焼ける。
ボランチは迷子だった。
攻めるのか、
守るのか。
中途半端な位置を走り回るだけ。
フォーメーションなんて、もうない。
ただ混乱だけがあった。
そして失点。
0 : 4
さらに失点。
0 : 5
足をつって倒れる選手。
交代!

入った若手は、まだこのスピードについていけない。
パスがずれる。
タイミングが合わない。
そこを突かれる。
カウンター。
失点。
0 : 6
最後の数分は、誰も覚えていない。
ただ時間が早く過ぎてほしいと思っていた。
ホイッスル。
試合終了。
歓声は相手側だけ。
オレンジの選手たちは、
ただ静かに歩き出す。
誰も目を合わせない。
誰も何も言わない。
しばらくして、
誰かがぽつりと呟いた。
"悪いけど、6点で済んでよかったな。"
その言葉が、
妙に現実的だった。
悔しいというより、
ただ疲れていた。
完全な敗戦だった。
その夜。
スタジアムを出ても、
誰もすぐには帰らなかった。
ロッカールームの前で、
スパイクを脱ぎながら、ただ黙って座っている。
6失点。
完敗。
今日もいつもの通り、
走った。
声も出した。
気持ちも切らさなかった。
それでも勝てなかった。
なぜだろう。
個人の努力が足りなかったのか。
気合が足りなかったのか。
たぶん、
違う。
フォーメーションが崩れていた。
役割が曖昧だった。
守備と攻撃を同時にやろうとして、
どちらも中途半端になっていた。
つまり
"戦い方"そのものが間違っていた。
ここまで読んで、
"なんのサッカー小説だ?"と思った方もいるかもしれません。
でも実は、これはサッカーの話ではありません。

これは、
いま私たちの開発組織で実際に起きていた出来事を、
サッカーに置き換えて書いただけの話です。
技術負債の対応と、
現行サービスの運用と、
新機能の開発を、
同じメンバーで、同時に、全部やろうとしていた。
その結果が
0 : 6
でした。。。
第2部
組織を作り直した理由 ー Conway’s Law と minma の設計思想
前回は、サッカーの試合に例えて
minmaがなぜ押し込まれ続けたのかを書きました。
第2部では、
なぜ負けたのか。
どうチームを組み直したのか。
そして、これからどう戦うのか。
実際に私たちが行った組織設計の話をします。
ここからは、テックブログとして、少し真面目な内容です。
問題の本質は"技術"ではなかった
最初に結論から言います。
当時の課題は、
- 言語選定
- フレームワーク
- クラウド構成
- CI/CDの自動化
といった技術的な選択ではありませんでした。
もちろん、改善余地はありました。
けれど、それは本質ではなかった。
本質はもっと手前。
市場の変化に対して、組織が追いつけなくなっていたこと。
市場は止まらない

minma は15年以上続くサービスです。
その間に、
- ユーザーの行動は変わり
- デバイスは変わり
- 期待される体験は変わり
- 競争環境も変わり
市場は常に変化します。
プロダクトも、成長とともに複雑になります。
けれど、組織構造は一度固まると、
簡単には変わりません。
その結果、
市場は動いているのに、
内部の意思決定と開発構造は、
ゆっくりになっていく。
このズレが、徐々に効いてきます
そして気づいたときには、
「押し込まれ続ける試合」になっている。
当時の構造
当時のminmaは、以下を同時に抱えていました。
- 技術負債の返済
- 新規機能開発
- 既存運用
- 障害対応
- インフラ改善
- エンジニア採用・育成
そしてこれらを、
同じメンバーが、同時に、全部やっていた。
つまり、
全員 = 刷新 + 運用 + 障害 + 改善 + 採用 + 育成
一見、効率的に見えます。
全員が全部できる。
柔軟で、強そうに見える。
でも、強度が上がると崩れます。
- コンテキストスイッチが増える
- 専門性が育たない
- 設計が後回しになる
- 火消しが優先される
- 技術負債が積み上がる
- 育成の時間が削られる
特に育成は、
緊急ではないが重要な仕事です。
緊急対応が続く組織では、
真っ先に削られる。
その結果、
未来の戦力が育たない。
努力の問題ではありません。
構造的に、市場適応力が落ちる設計でした。
Conway’s Law
ここで重要なのが、
私がずっと信じている法則です。

Conway’s Law
システムを設計する組織は、
その組織のコミュニケーション構造を反映した設計を生み出してしまう
組織が曖昧であれば、
- モノリス化
- 責任不明コード
- 依存の肥大化
- 技術負債の蓄積
が自然に起きます。
組織が責任単位で分離されていれば、
- API境界は明確になり
- サービスは疎結合になり
- 変更は容易になり
つまり、
アーキテクチャは市場適応力の鏡であり、
その根本は組織設計にある。
組織がモノリスなら、
どんなマイクロサービスも、やがてモノリスに戻る。
技術刷新ではなく、適応構造への刷新

今回私たちが目指したのは、
一度きりの「技術刷新」ではありません。
市場の変化を読み、
継続的に構造を調整できる組織にすること。
そのための設計原則はシンプルでした。
- トレードオフしない
- 役割を混在させない
- 責任を固定する
新しい組織構造
刷新チーム → 未来を作る(攻撃)
即応チーム → 今日を守る(守備)
SRE → 基盤最適化(制御)
QA → 品質保証(リスク管理)
ポイントは「役割固定」です。
コンテキスト混在を排除し、
責任境界を明確にする。
これにより、
組織分離 → 責任明確 → サービス分離 → 疎結合化
が自然に起きます。
そしてそれが、
市場の変化に適応できる構造を作ります。
現在地
誤解してほしくないのは、
これまでのやり方が間違いだったわけではない、
ということです。
その時点では最適だった。
けれど、
環境が変われば、最適も変わる。
私たちはまだ完成していません
- 技術負債は残っています
- 障害もゼロではありません
- 課題は山積みです
ただ、
以前は「耐える構造」でした。
今は「適応できる構造」に変わりつつあります。
ここが、大きな違いです。
そして、ここで終わりではありません。
今の組織も、
やがてまた変わります。
いまは最適化されたチーム構造かもしれません。
けれど、市場が変われば、
プロダクトが変われば、
組織の規模が変われば、
最適もまた変わります。
最後に、

もしこの記事を読んで、
「この組織設計、ちょっと面白そうだな」
と思った方。
私たちは、
万能な選手を求めているわけではありません。
ポジションを持ち、
その責任に集中できる人を求めています
minmaでは
入団テスト(採用)を常時開催中です。
| フォワードも、 |
 |
| ボランチも、 |
 |
| センターバックも、 |
 |
| サイドバックとGKも、 |
 |
市場は止まりません。
だから私たちも、止まりません。
次回予告
次回は、
各チームの具体的なミッション
実際の取り組み
連携方法を紹介します。
より実践的な内容になる予定です。