
こんにちは。みんなのマーケットでCTOをしている戸澤です。
くらしのマーケットは扱っている出張サービスの種類(カテゴリ)が多く、カテゴリ毎にプロダクト開発が必要になります。 その開発をより大規模、かつ、高速に進めていくためにベトナムでの開発スタートしました。その事例を紹介します。
こんにちは。みんなのマーケットでCTOをしている戸澤です。
くらしのマーケットは扱っている出張サービスの種類(カテゴリ)が多く、カテゴリ毎にプロダクト開発が必要になります。 その開発をより大規模、かつ、高速に進めていくためにベトナムでの開発スタートしました。その事例を紹介します。

こんにちは。みんなのマーケットでCTOをしている戸澤です。
2020年のコロナウイルス流行から当社はフルリモートワークへ働き方を切り替えました。 現在は出社する人数も増えていますが、現在も大多数はリモートワークをしています。
今回、リモートワークで使用していたVPNをやめて、Cloudflare Accessと切り替えた事例を紹介します。

こんにちは。みんなのマーケットでUI/UXデザイナーをしている「みそ」です。
これまでの「くらしのマーケット」のロゴの変更目的をまとめました。
我々デザイナーがプロダクトを作る上で何を大事にしているのか、どういう基準で判断しているのか。プロダクト、サービスが今どういう状態にあるのか。このあたりのことが参考になればど思います。

こんにちは、バックエンドエンジニアの富永です!
今年も早いもので、もう11月ですね〜。
最近東京では過ごしやすい気候が続いています。寒さが苦手な自分にとってはずっとこのままでいてほしいな〜、と願って止まない今日この頃です。
さて私事ですが、今年6月にみんなのマーケットにジョインし、レポート作成機能という新規機能の開発を担当させていただきました。
その際に、Amazon S3(以下、S3)・Amazon Elastic Container Service(以下、ECS)を活用し開発しました。前職で少しAWSの経験はあったのですが、AWS SDKを使っての開発はほぼ初めての経験で、機能要件を満たすためにそれぞれのサービスを調べたり、操作する中で勉強になったことがありました。
そこで、本記事では、開発したレポート作成機能の説明とS3・ECSに関する小話をお伝えしたいと思います。
現在、コンサルティング本部の担当者が業務の一環で利用している、レポートがあります。 従来、このレポートは下記フローチャートの流れで作成していました。レポート作成は、月2〜3回の頻度で発生しており、その度にコンサルティング本部の担当者と、SREエンジニアの担当者の間でコミュニケーションが発生し、お互いに煩わしさを感じていました。 そこで、このコミュニケーションコストを削減することを目的に、今回のレポート作成機能の開発を行いました。
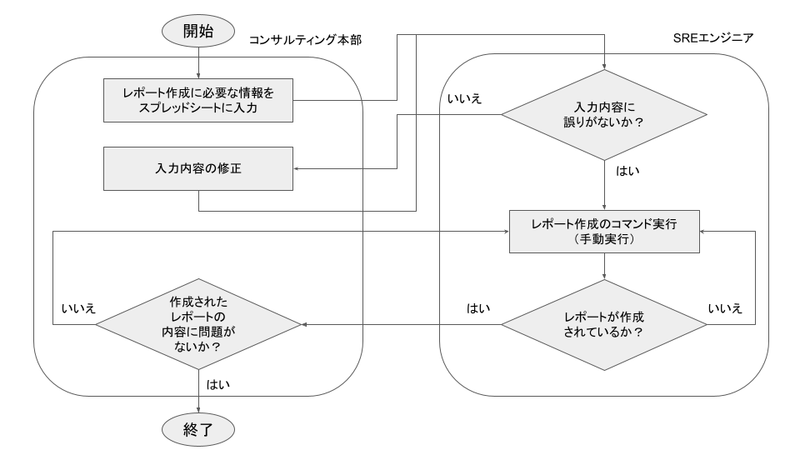 図1.レポート作成のフローチャート(レポート作成機能開発前)
図1.レポート作成のフローチャート(レポート作成機能開発前)
開発したレポート作成機能の画面イメージ1は、以下の通りです。
コンサルティング本部の担当者は、レポート作成画面で必要な情報を入力し、「レポートを作成」ボタンをクリックします。
入力した情報を元に、システム内部でECSタスクを実行するコマンドを生成し、ECSタスクを実行します。
実行したECSタスクの中では、複数種類のレポートを作成しており、レポートの作成が完了したら、そのファイルをS3にアップロードするようになっています。
なおレポートはhtmlファイルになっており、レポート確認画面の「開く」リンクをクリックすると、レポートを別タブで開くことができるようになっています。
 図2.レポート作成画面の画面イメージ
図2.レポート作成画面の画面イメージ
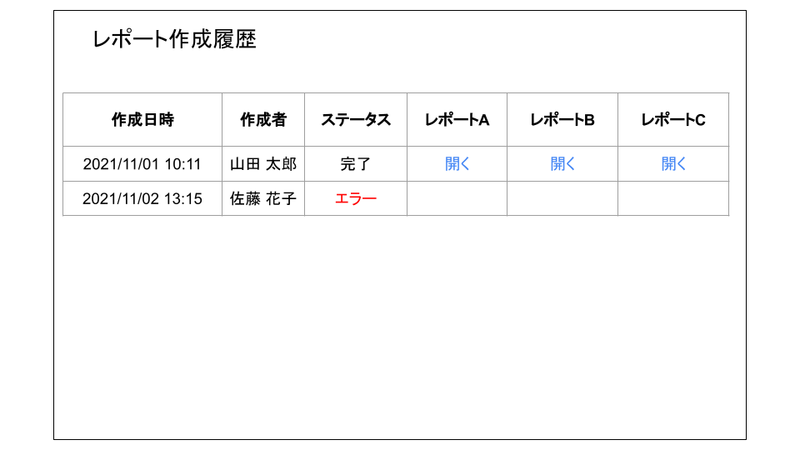 図3.レポート確認画面の画面イメージ
図3.レポート確認画面の画面イメージ
本章では、S3・ECSについて調べたり操作していく中で分かったことについて、5点共有させていただきます。
一度のレポート作成で、複数種類のレポートファイルが作成されるため、それらを一つのフォルダの中にまとめ、そこからファイルを取得するように実装しています。
これを実装する際に、AWS マネジメントコンソールを使って、一つのフォルダの中に、複数種類のレポートファイルをアップロードした後の状況を再現し、ファイル取得以降の処理を実装しようとしていました。
この際に、レポートファイルのみをオブジェクトとして取得したかったのですが、設定方法によっては期待通りに動かないことがあったため、そのときに学んだことを共有させていただきます。
例えば、「hoge」バケットの中にfuga/piyo.txtのファイルをアップロード(保存)する場合を考えてみましょう。
hoge/(バケット) └ fuga/ └ piyo.txt
AWS マネジメントコンソールからこの設定を行う方法として、以下の2パターンがあります。
パターン1、パターン2の操作手順は、それぞれ以下の通りです。2
1.「hoge」バケットの「アップロード」ボタンをクリックします。
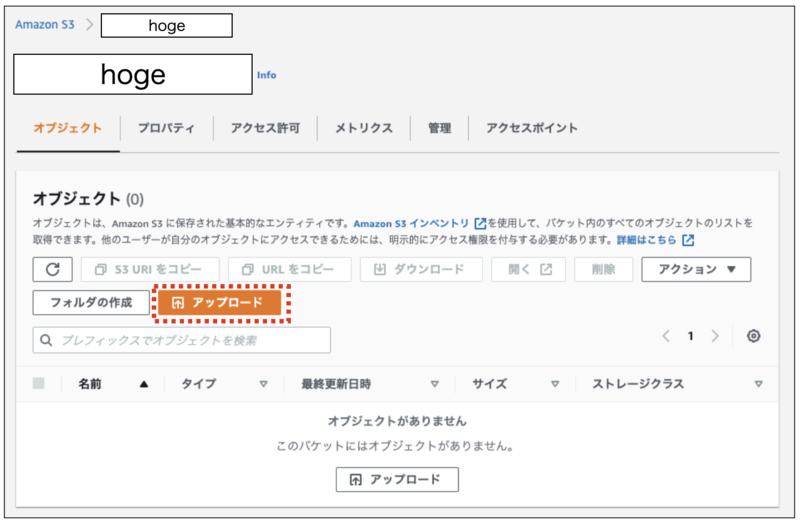
2.開いた画面で「フォルダの追加」ボタンをクリックし「fuga」フォルダを選択した後、「アップロード」ボタンをクリックします。
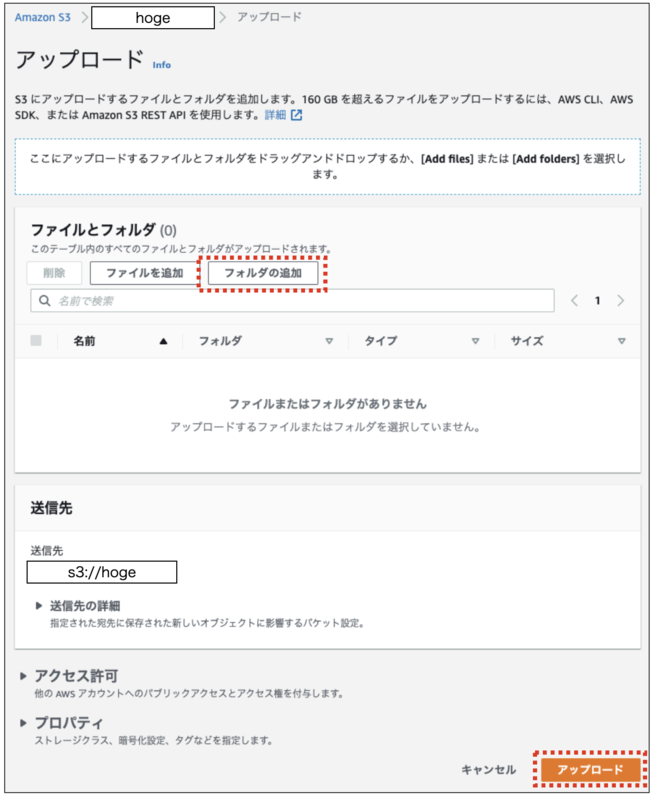
1.「hoge」バケットの「フォルダの作成」ボタンをクリックします。
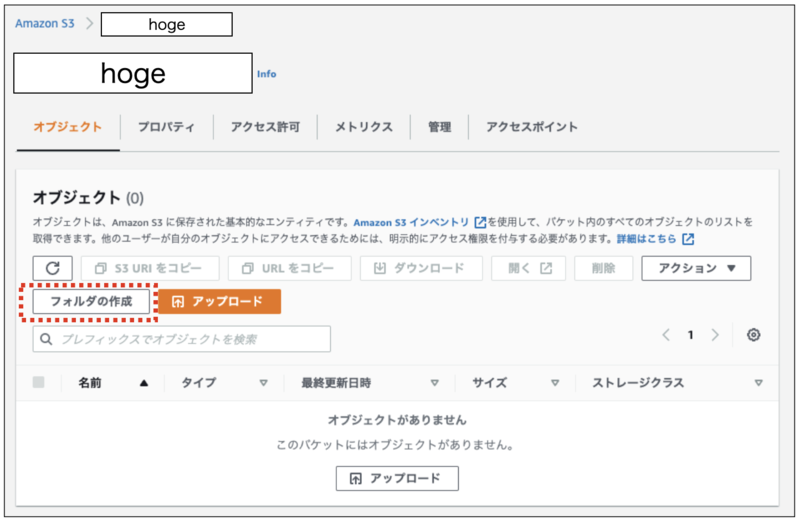
2.開いた画面で「フォルダ名(fuga)」を入力し「フォルダの作成」ボタンをクリックします。
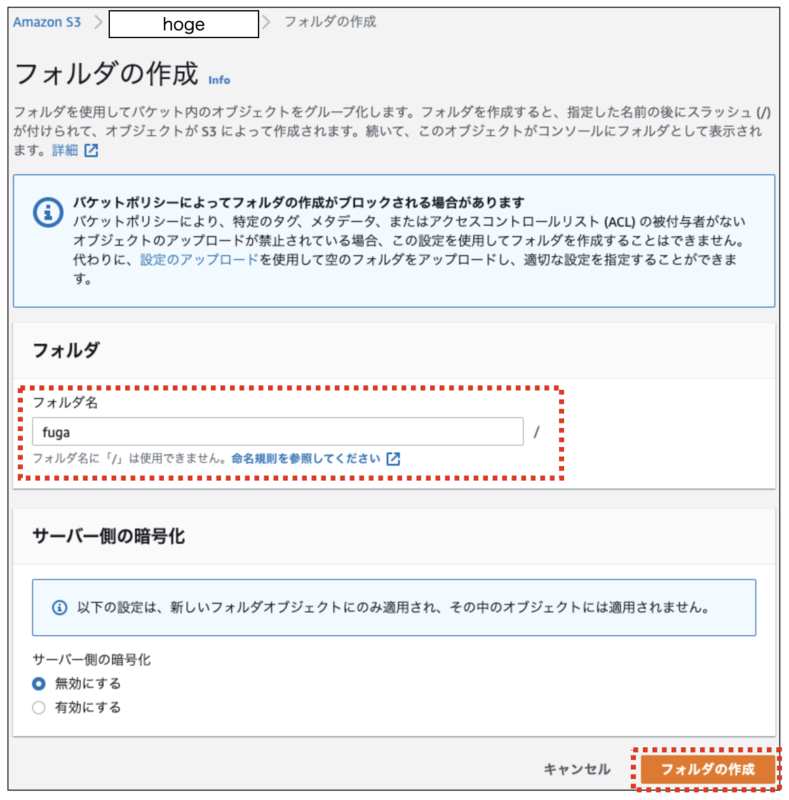
3.「fuga」フォルダに移動し、「ファイルを追加」ボタンをクリックし「piyo.txt」ファイルを選択後、「アップロード」ボタンをクリックします。
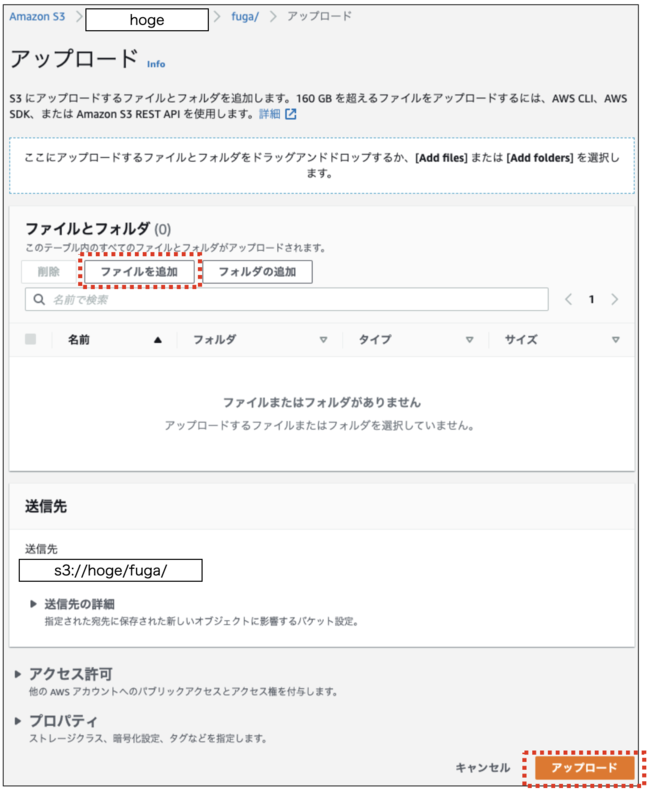
以上のパターン1,2の手順を実施した後、どちらも画面上には、以下のような形で「piyo.txt」を確認することができます。

次に、それぞれの操作完了後、「hoge」バケットの中身を取得します。
■パターン1の結果
$ aws s3api list-objects --bucket hoge
{ "Contents": [ { "Key": "fuga/piyo.txt", "LastModified": "2021-11-10T02:48:47.000Z", "ETag": "\"f290d73a3d0ba856b5d82eff7a1e8ece\"", "StorageClass": "STANDARD", "Size": 3, "Owner": { "DisplayName": "(Onwerの表示名)", "ID": "(OnwerのID)" } } ] }
■パターン2の結果
$ aws s3api list-objects --bucket hoge
{ "Contents": [ { "Key": "fuga/", "LastModified": "2021-11-10T02:48:46.000Z", "ETag": "\"af572fda0c25b593deaecb6663a081df\"", "Size": 0, "StorageClass": "STANDARD", "Owner": { "DisplayName": "(Onwerの表示名)", "ID": "(OnwerのID)" } }, { "Key": "fuga/piyo.txt", "LastModified": "2021-11-10T02:48:47.000Z", "ETag": "\"f290d73a3d0ba856b5d82eff7a1e8ece\"", "StorageClass": "STANDARD", "Size": 3, "Owner": { "DisplayName": "(Onwerの表示名)", "ID": "(OnwerのID)" } } ] }
パターン1だと「piyo.txt」しか存在しません。一方、パターン2だと「piyo.txt」と「fuga」フォルダがオブジェクトとして存在します。
これは、S3のデータモデルがフラットな構造になっていることが起因しています。
S3では、バケットを作成し、そのバケットにオブジェクトが直接格納されます。そのため、バケットの中には、そもそもフォルダという概念はなく「フォルダの作成」で、見た目としての「フォルダ」を作成した場合も、内部的にはオブジェクトとして管理さています。
今回のように、何も意識せずに、AWSマネジメントコンソールで「フォルダの作成」の操作を行ってしまうと、本来想定していなかった不要なオブジェクトを生成してしうまうことになってしまうため、意外と注意が必要だなと思いました。
なおAWS CLIやAWS SDKを使って、S3にファイルをアップロードする場合も同様の注意が必要です。
以上の話を踏まえ、今回の開発ではフォルダはオブジェクトに含めたくなかったため、パターン1の方法でアップロードし、開発を進めていくようにしました。
Amazon S3 のデータモデルはフラットな構造をしています。バケットを作成し、バケットにオブジェクトを保存します。サブバケットやサブフォルダの階層はありません。ただし、Amazon S3 コンソールで使用されているようなキー名のプレフィックスや区切り記号を使用して論理的な階層を暗示できます。
レポートのhtmlファイルは、画面を描画するタイミングで署名付きURLを発行し、それをアンカータグにセットすることで、別タブで開くことができるようにしています。
署名付きURLを使うことで、本来はアクセス権限がないユーザでも、対象のファイルにアクセスすることが可能になります。
この署名付きURLには、有効期限があり、デフォルトでは15分に設定されています。
開発当初、有効期限を考慮できておらず、15分経過した後にページをリロードすると以下のようなエラー画面が表示されていました。
ちなみに有効期限は最大7日間、設定することができます。
 図10.有効期限切れの画面例
図10.有効期限切れの画面例
有効期限 デフォルト15分(「Options Hash」部分を参照)
Options Hash (params): Expires (Integer) — default: 900 — the number of seconds to expire the pre-signed URL operation in. Defaults to 15 minutes.
IAM ユーザー: 最大 7 日間有効 (AWS Signature Version 4 を使用した場合)
コンサルティング本部の担当者から「古いレポートは見れなくしてほしい」という要望があり、対応する必要がありました。
そこで活用したのが、S3のオブジェクトのライフサイクルになります。
オブジェクトのライフサイクルを設定することで、バックアップの取得、削除を自動で行ってくれます。
ここで注意しなければいけないのが、ライフサイクルの設定時間です。
Amazon S3 は、ルールに指定された日数をオブジェクトの次の新しいバージョンが作成された時間に加算し、得られた日時を翌日の午前 00:00 (UTC) に丸めることで、時間を算出します。たとえば、バケット内に 2014 年 1 月 1 日の午前 10 時半 (UTC) に作成されたオブジェクトの現行バージョンがあるとします。現行バージョンを置き換えるオブジェクトの新しいバージョンが 2014 年 1 月 15 日の午前 10 時半 (UTC) に作成され、3 日間の移行ルールを指定すると、オブジェクトの移行日は 2014 年 1 月 19 日の午前 0 時 (UTC) となります。
上記から、日数計算の開始は 0時0分(UTC) とありますので、日本時間では 午前9時00分 から計算を開始するようです。 また、作成日時は丸めて算出されるということですので、削除日時は以下のようになります。
例:削除期間を1日に設定した場合(以下、全て日本時間) * 作成日時:2021年11月10日 午前8時59分→ 削除日時:2022年11月11日 午前9時00分 * 作成日時:2021年11月10日 午前9時01分→ 削除日時:2022年11月12日 午前9時00分
これを考慮し、日本時間の30日後に削除をしたかったため、ライフサイクルは以下のように設定をしました。
しかし、テストや運用で削除結果の様子を見ていたところ、午前9時00分ピッタリに削除されず、削除指定日のその日中には削除されるといった具合でした。
これに関しては公式からも、このような回答が出ているので、物理的なファイルの削除にはタイムラグがあるのかなと思っております。
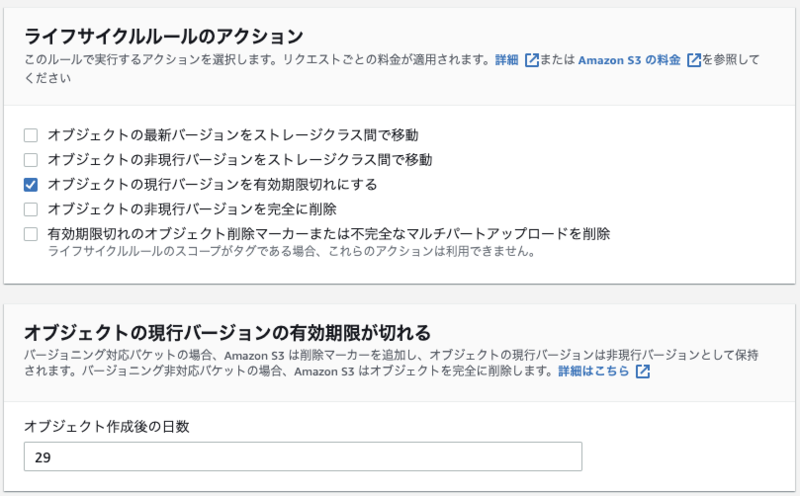 図11.ライフサイクルの設定画面
図11.ライフサイクルの設定画面
最後に、内部設計の際に調べていて気づいたことを共有させていただきます。
レポート確認画面では、レポート作成を実行したタイミングごとに、各種レポートのリンクと合わせて以下の情報を出力しています。
この情報をどこに保存して、参照するのかについて、検討する必要がありました。 そこで、色々調べた結果、以下の4つの案について検討しました。
これは一瞬で却下となりました。 わざわざテーブルの新規作成や、カラム追加を行って管理するほど重要な情報ではないためです。
次にECSタスクの実行結果を取得する案を考えました。 調べたところ、ListTasksというコマンドがあり、実行結果を一覧として取得することができそうでした。
しかし、よく見てみてると以下のような記述があり、タスクが停止したものは1時間しか保存されず、永久的に参照することは難しいようでした。そのためこの案は、却下となりました。
Recently stopped tasks might appear in the returned results. Currently, stopped tasks appear in the returned results for at least one hour.
他にも情報収集を行っていたところ、S3にアップロードするオブジェクトに対して、ユーザ定義のメタデータ情報を付与できることを知りました。
オブジェクトをアップロードするときに、そのオブジェクトにメタデータを割り当てることもできます。このオプション情報は、オブジェクトを作成するための PUT リクエストまたは POST リクエストを送信するときに、名前と値 (キーと値) のペアとして指定します。REST API を使用してオブジェクトをアップロードするときは、オプションのユーザー定義メタデータ名を「x-amz-meta-」で始め、他の HTTP ヘッダーと区別する必要があります。
例えばS3にレポートのhtmlファイルをアップロードする際に、今回画面上に表示したい情報をメタデータとして付与し、そこを参照することで、今回の要件を満たすことができると考えました。
しかし、この案は採用しませんでした。確かに要件は満たせそうだったのですが、今回はレポート作成を実行したタイミングごとの情報があれば十分だったので、この案は却下となりました。
レポートファイルごとに実行状況のステータスなどが必要な場合は、こちらを採用しても良かったのかなと思っています。
今回の開発では案4を採用し、次のように実装しました。
ECSタスクの実行ステータスを「作成中」として、下記情報を含んだjsonファイルを生成し、レポート作成前にS3にアップロードします。
全てのレポートの作成が完了したら、ECSタスクの実行ステータスを「完了」にしたjsonファイルを、S3にアップロードします。
なおレポート作成中にエラーが発生した場合は、ECSタスクの実行ステータスを「エラー」にしたjsonファイルを、S3にアップロードします。
ECSタスクの実行開始までに若干のタイムラグはありますが、シビアな同期は求められず、やりたかったことも実現できたため、今回の開発では案4を採用しました。
本記事では、レポート作成機能の説明とS3・ECSに関する小話をまとめました。
改めて、クラウドサービスについて知っていることで選択肢の幅が広がるな、と実感しました。それと同時に、全てをクラウドサービスで解決するのではなく要件に合わせてベストな選択をしていくことが大切、ということも実感しました。
また、くらしのマーケットでは他のAWSサービスも活用しているため、それらについても学んでいきたいなと思いました!
最後にみんなのマーケットでは、くらしのマーケットのサービス開発を一緒に盛り上げてくれるエンジニアを募集しています!
詳しくは、こちらをご覧ください。

こんにちは、バックエンドエンジニアのキダです。 最近DjangoのアプリケーションにてRead Replica(リードレプリカ)構成を検証してみたので、その内容を共有しようと思います。
この記事では、DjangoのアプリケーションからDB操作にはDjango ORMと、Aldjemyを使う前提の構成になります。
Django ORMやAldjemyそのものについては以下のWebサイトをご参照ください。
まず前提として一般的なアプリケーションでのRead Replica構成について説明します。 databaseをWriter(Main)とReader(Replica)に分割して、負荷の高い書き込み処理と読み取り処理を、接続するdatabase単位で分けることにより、パフォーマンスを高める事ができる構成です。 Readerは2台以上構成する事も可能で、高負荷がかかった時にスケールアウトすることもできるので、スケーラビリティの高い構成と言えます。
Amazon Auroraなどのサービスでは、コンソールから簡単にRead Replicaインスタンスを追加・削除する事が可能です。 AuroraのRead Replicaは高い同期性能を持っていて、15ミリ秒程度のラグでWriterの更新がReaderに同期されます。
アプリケーション側では接続するホストの設定によって、WriterとReaderどちらを使用するかを切り替えています。 例えば、くらしのマーケットの環境では、データダッシュボードとしてRedashを利用していますが、こちらは読み取り操作のみ実行できればいいのでReaderのDBにつながるような設定をしています。
今回はRead(読み取り)とWrite(書き込み)が両方発生する、Djangoのアプリケーションにてこちらの構成を考えてみます。
公式ドキュメントでは、以下の方法が紹介されています。
デフォルトdatabaseの他にReaderの接続情報を定義して、ルーティングを定義することができます。
ルーティングは細かい設定は不要で、実際に実行されるSQLに応じて、Read系操作はdb_for_readに定義した接続先、Write系操作はdb_for_writeに定義した接続先につながるようになっていました。
しかしこのDBルーティングの機能は完全では無く、以下の問題点がありました。
トランザクションやラグについては公式ドキュメントでも以下の通り言及されています。
The primary/replica (referred to as master/slave by some databases) configuration described is also flawed – it doesn’t provide any solution for handling replication lag (i.e., query inconsistencies introduced because of the time taken for a write to propagate to the replicas). It also doesn’t consider the interaction of transactions with the database utilization strategy.
以下のようなユーザー作成のAPIを考えてみます。
ルーティングにより、2.のユーザー作成のWrite操作はWriterに繋がり、3.のRead操作はReaderに繋がります。 Readerに作成されたユーザーデータが同期されるのはトランザクションがコミットされた後なので、3.のタイミングでは結果が取得できずエラーになってしまいます。
また、トランザクションを使っていない場合でも同期ラグによって、結果が取得できない事も起こり得ます。
クエリの接続先を見ていると、正常にルーティングできているものが多かったのですが、一部のWrite操作がReaderに繋がっている物も確認できました。
詳細を調べてみると、Aldjemyを使用したオブジェクトアクセスによるものはdb_for_readに定義した接続先に繋がっており、DBルーティングの機能では対応できない事がわかりました。
上記の結果を踏まえて、Django ORM・Aldjemyの両方でルーティング可能かつ、トランザクションの問題も発生しない方法を検討しました。
結論から言うと、DjangoのMiddleware実装によって、リクエスト単位で接続先のDBを切り替える事が可能でした。
Djangoではリクエスト単位で、処理の前後にMiddlewareとして共通処理を定義することができます。 今回はこのMiddlewareを利用して、APIリクエストの情報に応じて接続をルーティングする機能を実装しました。
# config.py MIDDLEWARE_CLASSES = ( # middlewareの設定以外は省略 'app.request_session.RequestMiddleware', ) DATABASES = { # writerのDB接続情報 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': 'name', 'USER': 'user', 'PASSWORD': 'password', 'HOST': 'writer_host_name', 'PORT': 5432 } }
# request_session.py from django.db import connections class RequestMiddleware(object): # リクエストを受け取った際の処理(DBセッションが作られる前) def process_request(self, request): for conn in connections.all(): conn.settings_dict["HOST"] = "writer_host_name" # GETリクエストの場合はReplicaを参照させる if request.method == "GET": conn.settings_dict["HOST"] = "reader_host_name" return # レスポンスを返す際の処理(DBセッションが作られた後) def process_response(self, request, response): for conn in connections.all(): if hasattr(conn, 'sa_session'): conn.sa_session.close_all() return response
こちらは一番シンプルな例ですが、全てのGETリクエストをReaderに接続させて、それ以外のリクエストはWriterに接続するMiddlewareの記載例になります。
connections.all()によって取得されるdb connectionはループで書いていますが、config.pyに記載されたデフォルトdatabase(Writer)のみです。
WriterとReaderはHOST以外は同じ接続情報でつながるようになっていて、HOST情報のみを切り替える実装になります。
こちらのHOSTを書き換えることによって、実際にDjango ORMやAldjemyによって実行されるdatabaseアクセスを切り替える事が可能でした。
ちなみにconnectionのsettings_dictは以下のようなオブジェクトになっていました。
{
'CONN_MAX_AGE': 0,
'TIME_ZONE': 'UTC',
'USER': 'user',
'NAME': 'name',
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'HOST': 'writer_host_name',
'PASSWORD': 'password',
'PORT': 5432,
'OPTIONS': {},
'ATOMIC_REQUESTS': False,
'AUTOCOMMIT': True
}
先程の実装ですが、複数のプロセスが立ち上がっている場合に、意図しない接続にならないかを確認しました。
conn.settings_dictの内容はプロセス単位でメモリが共有されているようでしたので、同一リクエスト内ではMiddlewareを通ってからレスポンスを返すまで、同じ接続情報を保持している事が確認できました。
# 確認用のコード from django.db import connections import os class RequestMiddleware(object): def process_request(self, request): for conn in connections.all(): print("request : [pid:" + str(os.getpid()) + "] [Method:" + request.method + "] [HOST:" + str(conn.settings_dict["HOST"]) + "]") conn.settings_dict["HOST"] = "writer_host_name" # GETリクエストの場合はReplicaを参照させる if request.method == "GET": conn.settings_dict["HOST"] = "reader_host_name" return def process_response(self, request, response): for conn in connections.all(): print("response: [pid:" + str(os.getpid()) + "] [Method:" + request.method + "] [HOST:" + str(conn.settings_dict["HOST"]) + "]") if hasattr(conn, 'sa_session'): conn.sa_session.close_all() return response
# 実行時ログ request : [pid:25] [Method:GET] [HOST:writer_host_name] ## 初回のリクエストはwriterを参照している response: [pid:25] [Method:GET] [HOST:reader_host_name] request : [pid:21] [Method:GET] [HOST:writer_host_name] ## 一つ前のリクエストとはプロセスが違うので、writerを参照している response: [pid:21] [Method:GET] [HOST:reader_host_name] request : [pid:25] [Method:POST] [HOST:reader_host_name] ## 前回のリクエスト時に変更された参照を持っている response: [pid:25] [Method:POST] [HOST:writer_host_name] request : [pid:25] [Method:POST] [HOST:writer_host_name] response: [pid:25] [Method:POST] [HOST:writer_host_name] request : [pid:21] [Method:GET] [HOST:reader_host_name] response: [pid:21] [Method:GET] [HOST:reader_host_name]
今回DjangoのアプリケーションのMiddlewareを使ったRead Replica構成について紹介しました。
Django ORMやAldjemyのDBセッション単位では無く、APIリクエスト単位でルーティング設定ができるので、使い勝手が良い処理だと思います。
例では全てのGETリクエストをシンプルにルーティングしていますが、WriterとReaderに50%ずつ接続したり、リクエストのURL毎にルーティングルールを定義したりできそうです。
みんなのマーケットでは、くらしのマーケットの開発を手伝ってくれるエンジニアを募集しています!
詳細はこちらをご覧ください!